Introduction
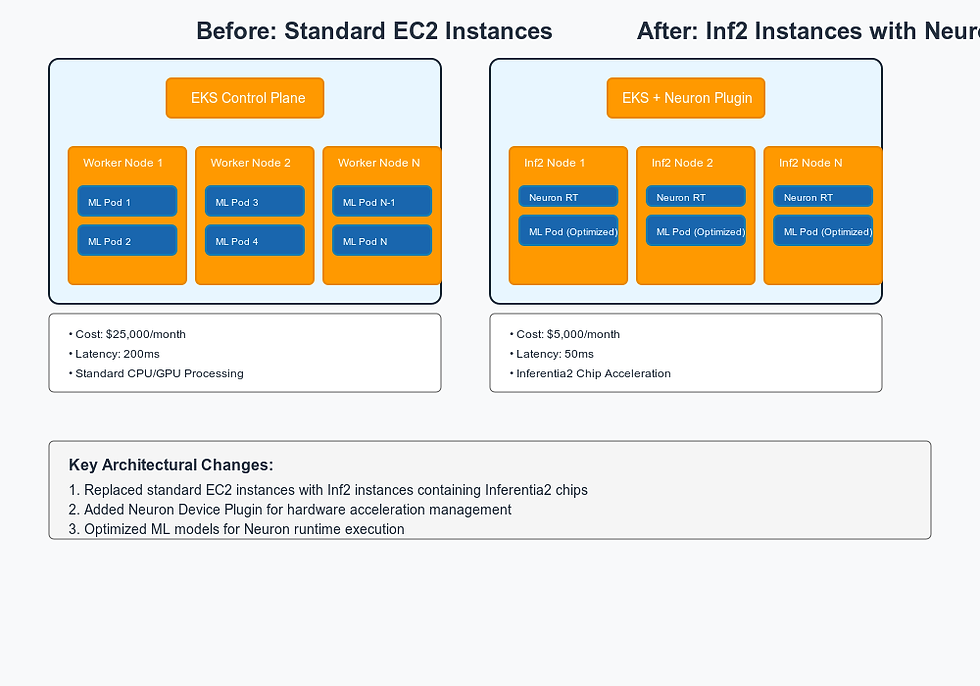
Running machine learning inference workloads on Amazon EKS can be expensive when using standard instances. Recently, we helped an ML team reduce their inference costs by 80% while improving performance by migrating to AWS Inferentia2 chips.
This guide details our step-by-step implementation process.
Initial Architecture Assessment
Before Optimization
100 inference pods running on standard EC2 instances
Infrastructure cost: $25,000/month
Average inference latency: 200ms
Using standard EKS deployment without ML-specific optimizations
Step 1: Setting Up AWS Neuron Environment
Install Neuron Tools
# Install Neuron CLI tools
sudo apt-get install aws-neuronx-tools
# Install Neuron container runtime
sudo apt-get install aws-neuronx-runtime-libConfigure Docker for Neuron
FROM public.ecr.aws/neuron/neuron-rtd:latest
COPY requirements.txt .
RUN pip3 install -r requirements.txt
RUN pip3 install torch-neuron neuron-cc
COPY model/ /opt/ml/model/
COPY inference.py .Step 2: Model Optimization for Inferentia2
Convert Model to Neuron Format
#python
import torch
import torch_neuron
# Load your PyTorch model
model = YourModelClass() model.load_state_dict(torch.load('model.pth'))
# Convert to Neuron format
model_neuron = torch.neuron.trace(
model,
example_inputs=[torch.zeros([1, 3, 224, 224])],
compiler_args=['--model-type=pytorch']
)
# Save the compiled model
model_neuron.save("model_neuron.pt")Step 3: EKS Cluster Configuration
Create EKS Cluster with Inf2 Support
eksctl create cluster \
--name ml-inference-cluster \
--node-type inf2.xlarge \
--nodes 3 \
--nodes-min 1 \
--nodes-max 5 \
--region us-west-2Install EKS Device Plugin
# neuron-device-plugin.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: neuron-device-plugin
namespace: kube-system
spec:
selector:
matchLabels:
name: neuron-device-plugin
template:
metadata:
labels:
name: neuron-device-plugin
spec:
containers:
- name: neuron-device-plugin
image: public.ecr.aws/neuron/neuron-device-plugin:latest securityContext:
allowPrivilegeEscalation: false
capabilities:
drop: ["ALL"]
Step 4: Deployment Configuration
Create Inference Deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: ml-inference
spec:
replicas: 100
template:
spec:
containers:
- name: inference
image: your-inference-image:latest
resources:
limits:
aws.amazon.com/neuron: 1
requests:
aws.amazon.com/neuron: 1
env:
- name: NEURON_RT_NUM_CORES
value: "1"
Configure HPA for Dynamic Scaling
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: ml-inference-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: ml-inference
minReplicas: 50
maxReplicas: 150
metrics:
- type: Resource
resource:
name: aws.amazon.com/neuron
target:
type: Utilization
averageUtilization: 75Step 5: Performance Monitoring
Set Up Prometheus Metrics
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: neuron-monitor
spec:
endpoints:
- port: metrics
interval: 30s
selector:
matchLabels:
app: ml-inference
Grafana Dashboard Configuration
{
"panels": [
{
"title": "Inference Latency",
"targets": [
{
"expr": "histogram_quantile(0.95, sum(rate(inference_latency_bucket[5m])) by (le))"
}
]
}
]
}Results and Optimizations
Performance Improvements
Latency reduction: 200ms → 50ms
Throughput increase: 4x
Cost reduction: $25K → $5K monthly
Key Optimization Techniques
Batch size optimization
Model compilation flags tuning
Resource allocation fine-tuning
Custom schedulers for pod placement
Best Practices and Lessons Learned
Model Optimization
Profile model performance before migration
Use neuron-top for runtime analysis
Optimize batch sizes for throughput
Infrastructure Management
Use spot instances for non-critical workloads
Implement proper node draining
Set up monitoring and alerting
Cost Management
Tag resources for cost allocation
Set up cost anomaly detection
Regular performance audits
Troubleshooting Guide
Common issues and solutions:
Compilation errors
neuron-cc --debug compile.logRuntime performance
neuron-monitor --watchNext Steps
For teams looking to implement similar optimizations:
Start with a small pilot deployment
Validate performance metrics
Gradually migrate production workloads
Monitor and optimize continuously
Need help implementing ML optimizations on EKS? Feel free to reach out in the comments or connect on LinkedIn.
Comments